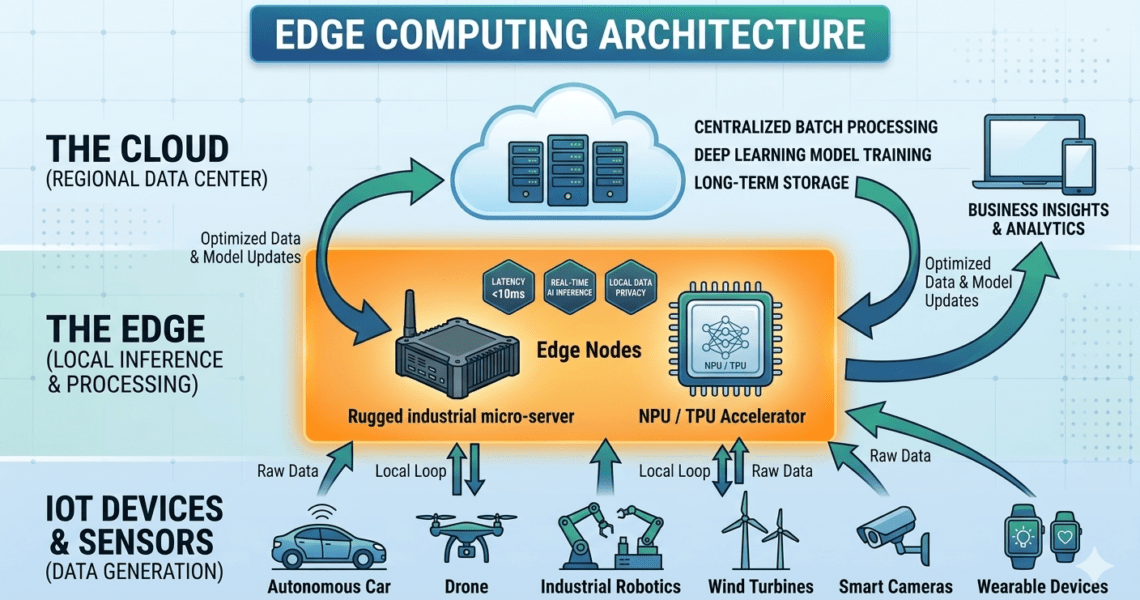
Edge Computing vs. Cloud: Der Kampf gegen die Latenz
In der klassischen Cloud-Infrastruktur werden Daten von Sensoren oder Kameras an ein entferntes Rechenzentrum gesendet, dort verarbeitet und das Ergebnis zurückgeschickt. Bei Echtzeit-Anwendungen, wie der autonomen Robotik oder industriellen Qualitätskontrolle, ist dieser Weg oft zu lang. Die Round-Trip-Time (RTT) und potenzielle Netzwerkschwankungen (Jitter) machen eine zuverlässige Steuerung unmöglich. Edge Computing löst dieses Problem, indem die Rechenleistung direkt an die „Kante“ (Edge) des Netzwerks verlagert wird.
Der entscheidende Vorteil liegt in der deterministischen Latenz. Da die Datenverarbeitung lokal auf der Hardware erfolgt, entfällt die Abhängigkeit von der Internetbandbreite. Technisch bedeutet dies, dass Inferenz-Zeiten im einstelligen Millisekundenbereich erreicht werden können. Dies ist nicht nur eine Frage der Geschwindigkeit, sondern der Datensouveränität: Sensible Informationen verlassen niemals das lokale Netzwerk, was die Einhaltung höchster Security-Standards (DSGVO-Compliance) nativ ermöglicht.
KI-Beschleuniger: Von der CPU zur NPU
Herkömmliche Prozessoren (CPUs) sind für sequenzielle Aufgaben optimiert, stoßen aber bei den massiv-parallelen Berechnungen neuronaler Netze schnell an ihre Grenzen. Hier kommen spezialisierte Inferenz-Beschleuniger zum Einsatz. Während eine GPU (Graphic Processing Unit) bereits deutliche Vorteile bietet, sind moderne NPUs (Neural Processing Units) oder TPUs (Tensor Processing Units) exakt auf die mathematischen Operationen von KI-Modellen (Matrix-Multiplikationen) zugeschnitten.
Ein Paradebeispiel ist die Google Coral TPU, die trotz einer Leistungsaufnahme von nur ca. 2 Watt bis zu 4 Billionen Operationen pro Sekunde (TOPS) leistet. Im Vergleich zu einem herkömmlichen x86-Server spart dies nicht nur massiv Energiekosten, sondern ermöglicht auch kompakte, lüfterlose Designs. Die Effizienz wird hierbei in Inferences per Watt gemessen – eine Kennzahl, die für industrielle Skalierungen wichtiger ist als die reine Rohleistung.
Architektur lokaler KI-Inferenz
Damit KI lokal performant läuft, müssen die Modelle optimiert werden. Dieser Prozess wird als Quantisierung bezeichnet. Dabei werden die Gewichte des neuronalen Netzes von hochpräzisen 32-Bit-Fließkommazahlen (FP32) auf kompakte 8-Bit-Ganzzahlen (INT8) reduziert. Technisch führt dies zu einem minimalen Genauigkeitsverlust, ermöglicht aber eine drastische Reduktion des Speicherbedarfs und eine enorme Beschleunigung auf spezialisierter Edge-Hardware.
| Merkmal | Cloud-KI (z.B. AWS SageMaker) | Edge-KI (z.B. NVIDIA Jetson) |
|---|---|---|
| Latenz | Hoch/Variabel (50ms – 500ms+) | Extrem niedrig/Fix (< 10ms) |
| Betriebskosten | Laufend (Pay-per-Request) | Einmalige Hardware-Investition |
| Datenschutz | Externer Datentransfer erforderlich | Vollständige On-Device-Kontrolle |
| Bandbreitenbedarf | Hoch (Rohdaten-Upload) | Minimal (nur Metadaten/Ergebnisse) |
Marktführer im Vergleich: NVIDIA Jetson vs. Google Coral
Für die Implementierung von Edge-KI haben sich zwei dominante Hardware-Plattformen herauskristallisiert, die unterschiedliche Anforderungen bedienen. Die NVIDIA Jetson-Serie (vom kompakten Orin Nano bis zum leistungsstarken AGX Orin) basiert auf der CUDA-Architektur. Ihr großer Vorteil ist die Vielseitigkeit: Sie kann nicht nur neuronale Netze beschleunigen, sondern übernimmt auch komplexe Bildverarbeitung und klassische Rechenaufgaben auf den GPU-Cores.
Im Gegensatz dazu ist die Google Coral Plattform (Edge TPU) ein reiner Inferenz-Spezialist. Sie nutzt das TensorFlow Lite Framework und ist darauf optimiert, spezifische Modellarchitekturen (wie MobileNet oder Inception) mit minimalem Energieaufwand auszuführen. Während der Jetson-Modelle eher als „KI-Workstations im Taschenformat“ fungieren, sind Coral-Module die erste Wahl für batteriebetriebene IoT-Geräte, bei denen jedes Milliwatt zählt.
Software-Stack: Von PyTorch zu TensorRT
Die größte Herausforderung beim Edge Computing ist die Portierung von Modellen, die auf High-End-Servern (mit FP32-Präzision) trainiert wurden, auf die begrenzte Hardware der Edge-Nodes. Hier kommen spezialisierte Compiler und Optimizer zum Einsatz. NVIDIA nutzt TensorRT, um das neuronale Netz zu analysieren, Layer zu verschmelzen (Layer Fusion) und die optimale Kernel-Belegung für die spezifische Hardware zu finden.
Dieser Prozess ist entscheidend für die Durchsatzrate (Throughput). Ein Modell, das nativ in Python unter PyTorch läuft, ist auf einem Edge-Gerät oft zu langsam. Erst durch die Konvertierung in ein optimiertes Format (wie ONNX oder TensorRT-Engine) wird die Hardware-Beschleunigung voll ausgenutzt. Dabei wird oft eine gemischte Präzision (Mixed Precision) verwendet: Unkritische Layer werden in 8-Bit berechnet, während sensible Schichten zur Wahrung der Genauigkeit in 16-Bit (FP16) verbleiben.
Pipeline-Optimierung: Zero-Copy und Memory-Management
Ein häufiger Flaschenhals in Edge-Anwendungen ist nicht die Rechenleistung selbst, sondern der Datentransport zwischen Kamerasensor, Arbeitsspeicher und KI-Beschleuniger. Professionelle Implementierungen nutzen Zero-Copy-Mechanismen. Hierbei wird der Speicherbereich, in dem das Kamerabild liegt, direkt für den Inferenz-Kern freigegeben, ohne dass die CPU die Daten physisch kopieren muss.
Dies reduziert die CPU-Last drastisch und verhindert, dass der Systembus zum Nadelöhr wird. Besonders bei Multi-Stream-Anwendungen, bei denen beispielsweise 8 IP-Kameras gleichzeitig analysiert werden sollen, ist ein effizientes Memory-Management (z. B. via Shared Memory unter Linux) der entscheidende Faktor für eine stabile Framerate. In der industriellen Praxis entscheidet oft die Effizienz dieser Daten-Pipeline darüber, ob eine Hardware-Einheit ausreicht oder ein teureres Modell beschafft werden muss.
Anwendungsfall: Lokale Video-Analytics im Einzelhandel
Ein praktisches Beispiel für den Vorteil von Edge-KI ist die anonymisierte Kundenstrom-Analyse. Anstatt Videostreams von 20 Kameras in die Cloud zu laden (was eine enorme Upload-Bandbreite erfordern würde), verarbeitet eine lokale Edge-Node die Bilder vor Ort.
Das System führt ein Object Tracking durch und sendet lediglich abstrakte JSON-Metadaten (z. B. „Person_ID: 45, Richtung: Eingang, Zeit: 14:02“) an das Dashboard. Die Privatsphäre bleibt gewahrt, da keine Gesichter oder personenbezogenen Videodaten das Gebäude verlassen. Zudem sinken die Betriebskosten für Cloud-Storage und Traffic auf nahezu Null, während die Reaktionszeit für Echtzeit-Benachrichtigungen (z. B. „Lange Schlange an Kasse 3“) massiv verbessert wird.
Local LLMs: Large Language Models ohne Rechenzentrum
Ein massiver Trend im Edge-Bereich ist die lokale Ausführung von Sprachmodellen (LLMs). Dank Architekturen wie Llama 3 oder Mistral, die speziell für effiziente Inferenz optimiert wurden, ist es heute möglich, leistungsfähige KI-Assistenten auf lokaler Hardware zu betreiben. Der Schlüssel hierzu ist die 4-Bit-Quantisierung (GGUF-Format), die den RAM-Bedarf so weit senkt, dass Modelle mit 7 oder 8 Milliarden Parametern auf einer Consumer-GPU oder einem Apple M-Chip flüssig laufen.
Technisch wird dies oft über Frameworks wie Ollama oder LocalAI realisiert, die eine standardisierte API bereitstellen. Für Unternehmen bedeutet dies den Schutz von Firmengeheimnissen: Interne Dokumente können analysiert und zusammengefasst werden, ohne dass ein Token jemals die eigene Firewall passiert. Die Token-Generierungsgeschwindigkeit (tokens per second) ist hierbei die entscheidende Metrik, um eine flüssige Interaktion ohne Cloud-Latenz zu gewährleisten.
Wirtschaftlichkeitsrechnung: Cloud-Gebühren vs. Hardware-Depreciation
Der Wechsel zu Edge Computing ist oft eine rein wirtschaftliche Entscheidung. In der Cloud werden Inferenz-Kosten meist pro 1.000 Token oder pro API-Call abgerechnet. Bei Systemen, die rund um die Uhr Daten verarbeiten (z.B. industrielle Sensorüberwachung), summieren sich diese OpEx (Operational Expenses) schnell zu fünfstelligen Beträgen pro Monat.
Dem gegenüber stehen die CapEx (Capital Expenditures) für Edge-Hardware. Eine Investition in einen Industrie-PC mit NVIDIA A2000 GPU amortisiert sich bei hoher Auslastung oft bereits nach 6 bis 12 Monaten. Da die lokale Hardware keine variablen Kosten pro Inferenz verursacht, sinken die Grenzkosten der Datenverarbeitung nahezu auf Null (abgesehen von minimalen Stromkosten). Dies ermöglicht Geschäftsmodelle, die in der reinen Cloud-Welt aufgrund der Transaktionsgebühren unprofitabel wären.
Hybride Strategie: Cloud für Training, Edge für Inferenz
Trotz der Vorteile der Edge stirbt die Cloud nicht vollständig, sondern wandelt ihre Rolle. Der moderne Ansatz ist die Hybride Cloud-Architektur. Hierbei wird die enorme Rechenpower der Cloud genutzt, um komplexe Modelle auf riesigen Datensätzen zu trainieren (Deep Learning). Das fertige, „schwere“ Modell wird anschließend komprimiert und auf die Edge-Geräte für die tägliche Inferenz ausgerollt.
Ein wesentlicher Bestandteil dieser Strategie ist das Federated Learning. Dabei lernen die Edge-Geräte lokal aus neuen Daten und senden lediglich die optimierten Modell-Gewichte (nicht die Rohdaten!) zurück in die Cloud. Dort werden die Erkenntnisse aller Nodes aggregiert, um ein verbessertes Global-Modell zu erstellen, das dann wieder per Over-the-Air Update (OTA) an alle Geräte verteilt wird. Dieser Kreislauf ermöglicht ein kontinuierliches Lernen des Gesamtsystems unter Wahrung der lokalen Privatsphäre.
Hardware-Härtung: Edge in rauen Umgebungen
Im Gegensatz zu klimatisierten Rechenzentren muss Edge-Hardware oft in Fabrikhallen, Fahrzeugen oder im Außenbereich bestehen. Dies erfordert eine industrielle Härtung. Passive Kühlkonzepte ohne bewegliche Teile (Lüfterlos) sind hier Standard, um Ausfälle durch Staub oder mechanischen Verschleiß zu verhindern.
Technisch müssen diese Geräte einen erweiterten Temperaturbereich (oft -40°C bis +85°C) abdecken und unempfindlich gegenüber Vibrationen (Schockresistenz nach MIL-STD-810) sein. Die Wahl des Betriebssystems fällt hier meist auf spezialisierte Real-Time OS (RTOS) oder gehärtete Linux-Distributionen (z.B. Ubuntu Core), die durch Read-Only-Dateisysteme sicherstellen, dass das System auch nach einem plötzlichen Stromausfall ohne Datenkorruption wieder sauber hochfährt.
Edge Cybersecurity: Die Dezentralisierung der Angriffsfläche
Während die Cloud ein zentrales, hochgesichertes Ziel darstellt, dezentralisiert Edge Computing die Angriffsfläche massiv. Jede lokale Edge-Node, sei es ein Gateway in einer Fabrikhalle oder ein Smart-Home-Server, ist ein potenzieller Eintrittspunkt für Cyber-Attacken. Die Herausforderung liegt darin, Tausende von physisch zugänglichen Geräten zu sichern, die oft über keine permanente IT-Überwachung verfügen.
Technisch erfordert dies einen Paradigmenwechsel hin zu Zero Trust Architekturen. Kein Gerät, kein Nutzer und kein Netzwerksegment darf implizit als vertrauenswürdig gelten. Jede Inferenz-Anfrage und jeder Datentransfer muss authentifiziert und autorisiert werden. Ein wesentlicher Baustein ist hierbei die Nutzung von Hardware Security Modules (HSM) oder Trusted Platform Modules (TPM) auf den Edge-Chips, um kryptografische Schlüssel manipulationssicher zu speichern und eine unveränderliche Geräte-Identität (Device Identity) zu gewährleisten.
Netzwerk-Segmentierung und Container-Isolierung
Ein kritischer Aspekt der Edge-Sicherheit ist die Netzwerk-Segmentierung. Die Edge-Hardware sollte niemals direkt aus dem öffentlichen Internet erreichbar sein. Sie agiert in einem isolierten Netzwerkbereich (z.B. VLAN), der nur über gesicherte VPN-Tunnel oder dedizierte IoT-Gateways mit der Cloud kommuniziert. Dies verhindert laterale Bewegungen von Angreifern innerhalb des Unternehmensnetzwerks, falls eine einzelne Node kompromittiert wird.
Auf Software-Ebene hat sich die Containerisierung via Docker oder Kubernetes (K3s) als Standard etabliert. KI-Modelle und Anwendungen laufen in isolierten Containern mit minimalen Rechten. Selbst wenn ein Angreifer die Kontrolle über eine Inferenz-App erlangt, ist es ihm durch die Container-Isolierung (Namespaces und Cgroups im Linux-Kernel) extrem erschwert, auf das Host-Betriebssystem oder andere Container zuzugreifen. Regelmäßige, automatisierte Over-the-Air (OTA) Updates der Container-Images sind essenziell, um Sicherheitslücken zeitnah zu schließen.
Zukunftsaussicht: Die Symbiose von Edge AI und 6G
Die nächste Mobilfunkgeneration, 6G, wird die Rolle der Edge AI fundamental verändern. Während 5G die Latenzzeiten bereits massiv gesenkt hat, wird 6G die KI-Fähigkeiten nativ in die Netzwerk-Infrastruktur integrieren (In-Network Computing). Die Basisstationen selbst werden zu leistungsfähigen Edge-Nodes, die Inferenz-Aufgaben für verbundene Geräte übernehmen können.
Dies ermöglicht ein Konzept namens Sub-Millisecond Latency. Anwendungen wie die telemedizinische Fernchirurgie oder die kooperative Schwarm-Intelligenz von autonomen Fahrzeugen werden durch diese extrem dichte, verteilte Rechenpower erst möglich. Die Edge stirbt nicht durch schnellere Netze, sie verschmilzt mit ihnen zu einem allgegenwärtigen, intelligenten Rechengewebe.
Green AI: Energieeffizienz als technischer Imperativ
Ein oft übersehener Vorteil der Edge-Inferenz ist der ökologische Fußabdruck. Das Training von KI-Modellen in riesigen Clustern verbraucht Terawattstunden an Energie. Doch auch die milliardenfache Inferenz in der Cloud summiert sich. Edge-Hardware, die auf spezialisierten RISC-V oder ARM-Architekturen basiert, führt die gleichen Berechnungen mit einem Bruchteil der Energie aus.
Da die Daten nicht über Tausende Kilometer durch Glasfasernetze und Router (die alle Strom verbrauchen) transportiert werden müssen, sinkt der CO2-Ausstoß pro Inferenz-Vorgang erheblich. „Smarte“ Systeme an der Edge können zudem so programmiert werden, dass sie nur bei relevanten Ereignissen aus einem Deep-Sleep-Modus erwachen (Event-driven Inferenz), was die Energiebilanz weiter optimiert. Für Unternehmen ist dies ein entscheidender Faktor für ihre ESG-Ziele (Environmental, Social, and Governance).
Checkliste: Die Wahl der richtigen Edge-Infrastruktur
Bevor man in Hardware investiert, müssen die technischen Anforderungen präzise definiert werden. Nicht jedes Projekt benötigt eine NVIDIA-GPU. Folgende Parameter sind entscheidend:
- Modell-Komplexität: Reicht ein quantisiertes INT8-Modell (Coral TPU) oder wird FP16-Präzision benötigt (Jetson)?
- Power-Budget: Steht Netzstrom zur Verfügung oder muss das System über Solar/Batterie laufen (< 5W)?
- Umgebungsbedingungen: Ist ein lüfterloses Design (IP67) aufgrund von Staub oder Feuchtigkeit zwingend erforderlich?
- Skalierbarkeit: Unterstützt die Hardware moderne Container-Orchestrierung (K3s), um hunderte Nodes zentral zu verwalten?
Fazit: Die Autonomie der Daten als Wettbewerbsvorteil
Edge Computing ist mehr als nur eine Methode zur Latenzreduktion; es ist die Befreiung der Künstlichen Intelligenz aus der Abhängigkeit zentraler Cloud-Giganten. Wer heute in lokale Inferenz-Infrastruktur investiert, sichert sich die volle Kontrolle über seine Daten, reduziert seine laufenden Betriebskosten drastisch und schafft die Basis für Echtzeit-Anwendungen, die in der Cloud schlicht unmöglich wären.
Die Zukunft der KI findet nicht nur in riesigen Rechenzentren statt, sondern in jeder Kamera, jedem Industrieroboter und jedem Smart-Home-Gateway. brixn.at wird diesen Weg begleiten und die technische Brücke schlagen zwischen theoretischer Informatik und der harten Hardware-Realität an der „Kante“ der digitalen Welt.
